Se você acompanha o mundo da inteligência artificial com um pouco mais de profundidade, vai notar um padrão: a maioria dos tutoriais, frameworks, documentações e ambientes de produção de IA assume que você está no Linux.
Não é coincidência. E não é preconceito contra Windows. É consequência de décadas de escolhas técnicas que fizeram do Linux o ambiente natural para computação de alto desempenho — e que hoje fazem ainda mais sentido no contexto da IA.
Eu uso Linux no dia a dia e posso dizer: a diferença não é só filosófica. É prática. Neste artigo vou explicar por que o Linux se tornou a casa da IA — e o que isso significa para quem quer trabalhar de verdade com modelos de linguagem, GPU e automação.
🏗️ A base histórica: Linux e computação de alto desempenho
Antes de existir “IA generativa”, já existia uma relação muito sólida entre Linux e computação intensiva. Supercomputadores, clusters de processamento, servidores de banco de dados, sistemas científicos — tudo isso rodava em Linux há décadas.
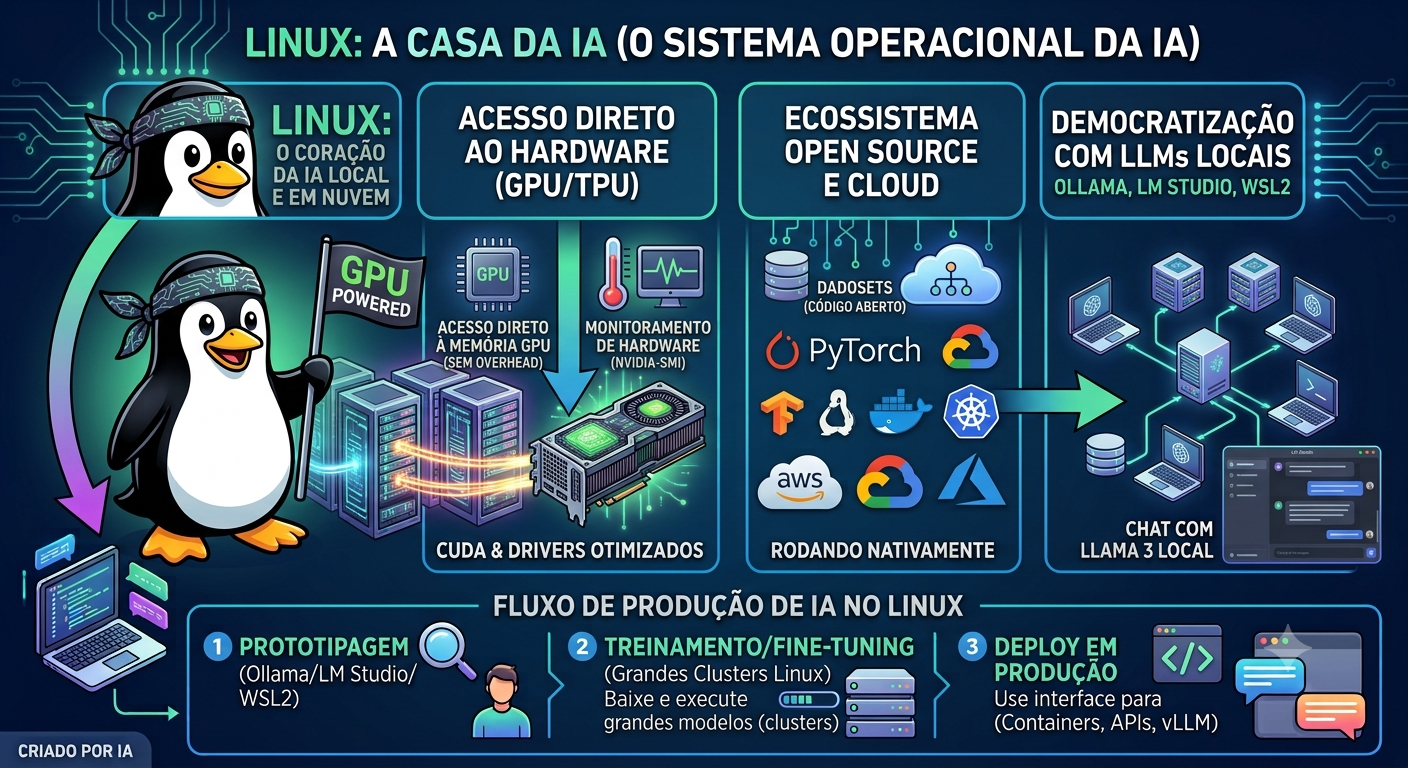
Os motivos são técnicos e históricos ao mesmo tempo. O Linux oferece controle granular sobre o hardware, ausência de camadas desnecessárias entre o software e o processador, estabilidade para processos que precisam rodar por horas ou dias sem interrupção, e um ecossistema de ferramentas de linha de comando que facilita automação em escala.
Segundo a lista Top500 — que ranqueia os supercomputadores mais poderosos do mundo — praticamente 100% deles rodam Linux. Quando a IA precisou de infraestrutura de alto desempenho, o terreno já estava preparado.
Quando as GPUs começaram a ser usadas para treinamento de redes neurais, os drivers, toolkits e frameworks foram desenvolvidos primeiro — e melhor — para Linux. O Windows veio depois, com suporte incompleto ou atrasado em muitos casos.
⚡ CUDA e ROCm: onde a IA realmente acontece
Para entender por que o Linux domina a IA, é preciso entender o que está por baixo de qualquer modelo de linguagem: o processamento massivo em GPU.
Treinar ou rodar um modelo de IA não é como executar um programa comum. São bilhões de operações matemáticas sendo realizadas em paralelo. A CPU não consegue fazer isso com eficiência — a GPU, sim. E para a GPU fazer esse trabalho, ela precisa de um toolkit que permita ao software se comunicar com o hardware de forma otimizada.
Plataforma de computação paralela da NVIDIA. É o padrão da indústria para treinamento e inferência de IA. Praticamente todos os grandes frameworks — PyTorch, TensorFlow, JAX — foram construídos com CUDA como base.
No Linux, a instalação e configuração do CUDA é mais direta, mais estável e mais bem documentada do que no Windows.
A alternativa open source da AMD para computação em GPU. Permite usar GPUs AMD para IA — uma opção importante dado o preço e disponibilidade das placas NVIDIA.
ROCm é suportado exclusivamente no Linux. No Windows, o suporte é mínimo ou inexistente para a maioria dos casos de uso de IA. Esse detalhe sozinho já explica muita coisa.
Se você quer usar sua GPU para rodar modelos locais com Ollama, fazer fine-tuning com QLoRA ou treinar qualquer coisa com PyTorch, o Linux vai entregar menos dor de cabeça com drivers, mais compatibilidade com as versões mais recentes dos toolkits e melhor desempenho no geral.
🐍 Python: a linguagem da IA mora no Linux
Python é a linguagem dominante da inteligência artificial. PyTorch, TensorFlow, Hugging Face Transformers, LangChain, LlamaIndex — tudo isso é Python. E Python simplesmente funciona melhor no Linux.
Não é que o Python não rode no Windows — roda. Mas quem já tentou gerenciar ambientes virtuais, dependências com compilações nativas, pacotes que precisam de bibliotecas do sistema e versões específicas de CUDA no Windows sabe que a experiência é infinitamente mais frustrante do que no Linux.
Com pyenv e virtualenv no Linux, criar ambientes Python isolados por projeto é simples e confiável. Cada projeto pode ter sua versão de Python e suas dependências sem conflito. No Windows, esse processo é mais propenso a erros de path, permissão e encoding.
Muitas bibliotecas de IA precisam compilar código C++ durante a instalação. No Linux, as ferramentas de compilação já estão disponíveis ou são instaladas com um comando. No Windows, isso frequentemente exige instalações extras, versões específicas do Visual Studio ou workarounds manuais.
A integração entre Python e o sistema operacional no Linux é muito mais natural. Chamar comandos do sistema, criar pipelines, agendar tarefas com cron — tudo isso funciona de forma mais previsível e com menos fricção do que no Windows.
🐳 Docker: o grande padronizador dos ambientes de IA
Um dos maiores problemas em projetos de IA é o famoso “funcionou na minha máquina”. Versões de Python, CUDA, bibliotecas e dependências do sistema variam de máquina para máquina — e uma diferença pequena pode quebrar tudo.
O Docker resolve isso empacotando o ambiente inteiro — sistema operacional, bibliotecas, código, dependências — num contêiner isolado que roda igual em qualquer máquina. Para IA, isso é essencial.
No Linux, o Docker roda de forma nativa — sem camadas de virtualização, sem overhead, com acesso direto ao kernel e à GPU via NVIDIA Container Toolkit. No Windows, o Docker precisa do WSL2 ou do Hyper-V, o que adiciona complexidade e pode criar problemas de desempenho e compatibilidade com GPU.
A maioria das imagens Docker para IA — Ollama, Open WebUI, AnythingLLM, servidores de inferência como vLLM e TGI — foram construídas e testadas em Linux. No Linux elas simplesmente funcionam. Em outros sistemas operacionais, o suporte é secundário e os problemas são mais frequentes.
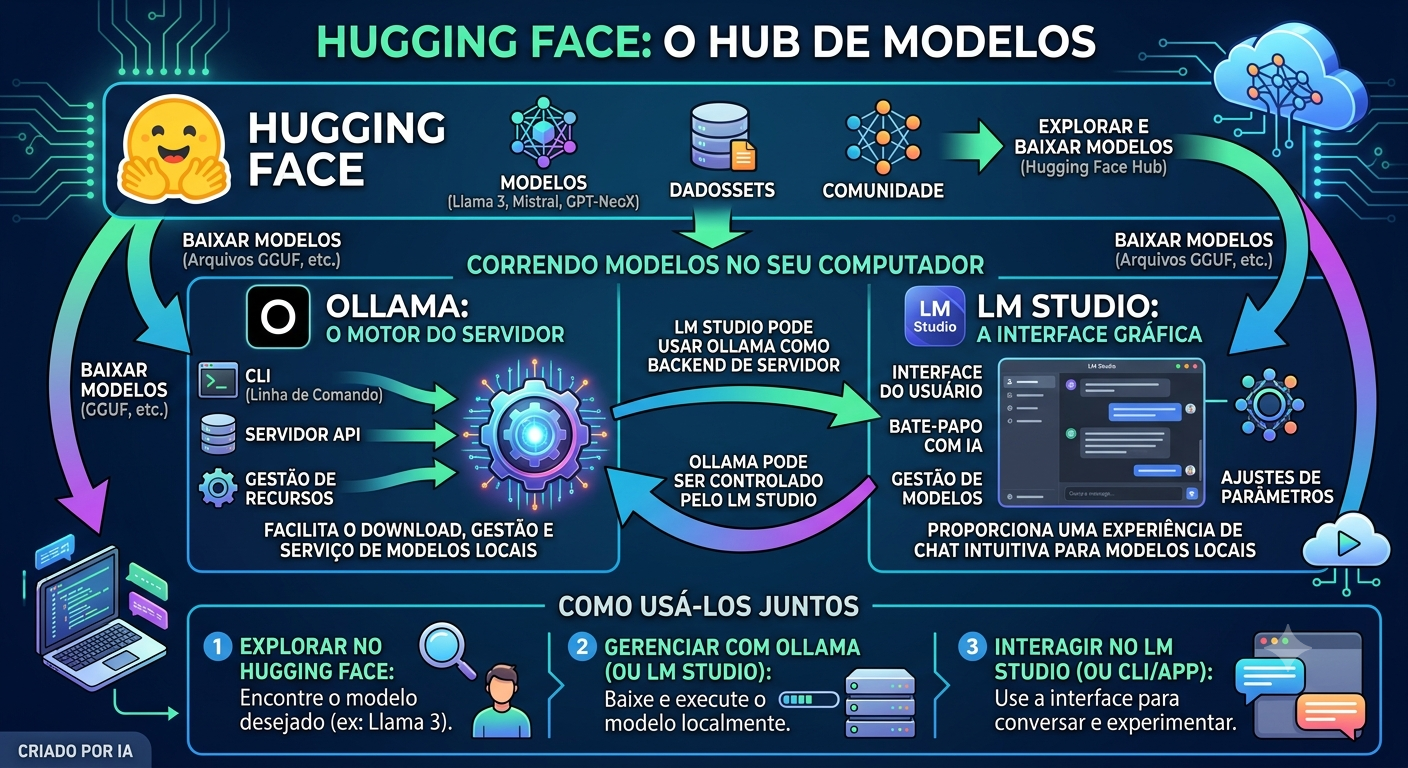
🦙 Ollama: nasceu no Linux, vive melhor no Linux
O Ollama — a ferramenta que virou padrão para rodar LLMs localmente — tem versões para Windows e macOS. Mas sua experiência mais completa, estável e com melhor suporte a GPU acontece no Linux.
No Linux, a instalação é um único comando, o serviço pode ser configurado para iniciar automaticamente, o acesso à GPU via CUDA ou ROCm é mais confiável, e a integração com outras ferramentas via API local é mais previsível.
curl -fsSL https://ollama.com/install.sh | sh
# Configurar como serviço que inicia automaticamente:
sudo systemctl enable ollama
sudo systemctl start ollama
Essa capacidade de rodar o Ollama como um serviço em segundo plano — que inicia automaticamente com o sistema e fica disponível para qualquer aplicação que precise da API local — é algo que no Linux funciona de forma nativa e elegante. É exatamente assim que servidores de IA são configurados em produção.
🔒 Estabilidade: IA precisa de um sistema que não te atrapalhe
Treinar um modelo leva horas. Às vezes dias. Rodas de fine-tuning, processos de ingestão de documentos para RAG, inferências em lote — tudo isso são processos longos que precisam de um sistema operacional que não interfira.
O Linux não reinicia sozinho para instalar atualização. Não abre pop-ups no meio de um processo. Não consome recursos de fundo com serviços desnecessários. Não tem um antivírus embutido que decide escanear arquivos enquanto o modelo está carregando.
- Controle total sobre processos em background
- Sem reinicializações automáticas forçadas
- Gerenciamento de memória mais eficiente
- Uptime de dias, semanas ou meses
- Sem overhead de interface gráfica (em servidores)
- Permissões e segurança granulares
- Atualizações que reiniciam sem aviso
- Antivírus interferindo em arquivos de modelo
- Paths com espaço e caracteres especiais
- Permissões que bloqueiam scripts
- WSL2 necessário para muitas ferramentas
- Comportamento diferente entre versões do Windows
🖥️ Servidores: onde a IA em escala acontece
Quando você acessa o ChatGPT, o Claude ou qualquer outro modelo via API, sua requisição está indo para um servidor. E esse servidor — com probabilidade muito alta — está rodando Linux.
A infraestrutura de IA em escala vive no Linux. AWS, Google Cloud, Azure — todas as grandes plataformas de nuvem têm o Linux como sistema operacional padrão para cargas de trabalho de IA. Os servidores de inferência mais usados — vLLM, Text Generation Inference (TGI), Triton — são desenvolvidos, testados e otimizados para Linux.
↓
Requisição chega a um servidor Linux na nuvem
↓
Servidor de inferência (vLLM / TGI) recebe a requisição
↓
GPU processa via CUDA no kernel Linux
↓
Resposta retorna em milissegundos
Desenvolver no mesmo sistema que você vai usar em produção elimina uma classe inteira de bugs e incompatibilidades. Quem aprende IA no Linux já está trabalhando no mesmo ambiente onde os modelos vão rodar quando forem para o ar. Isso não é detalhe — é uma vantagem real no dia a dia.
🪟 E o Windows? Dá para trabalhar com IA nele?
Dá — e cada vez mais ferramentas têm versão para Windows. O LM Studio, por exemplo, funciona muito bem no Windows e é uma ótima opção para quem quer explorar IA local sem migrar de sistema operacional.
O WSL2 (Windows Subsystem for Linux) também melhorou muito e permite rodar um ambiente Linux dentro do Windows com suporte a GPU. Para muitos casos de uso, é uma solução razoável.
O Windows é perfeitamente válido para quem está começando, explorando ou usando ferramentas com interface gráfica. Mas conforme você vai querendo ir mais fundo — fine-tuning, automações, servidores locais, integração com Docker, ROCm — vai encontrando mais barreiras. O Linux remove essas barreiras. Não é sobre preferência: é sobre onde o ecossistema de IA foi construído.
🎯 Por que o Linux é a casa da IA — resumido
O Linux não é a casa da IA por acidente ou por preferência de programadores. É porque as ferramentas, os drivers, os servidores e os frameworks foram construídos ali — e continuam sendo desenvolvidos com o Linux como ambiente principal.
Se você quer trabalhar de verdade com IA — não apenas usar, mas construir, automatizar, integrar e escalar — vai chegar num ponto em que o Linux vai facilitar muito mais do que qualquer outra opção. Não é sobre abandonar o que você já usa. É sobre entender onde o ecossistema cresceu e para onde ele continua crescendo.