Nos últimos anos, a inteligência artificial deixou de depender exclusivamente da nuvem. Hoje é possível executar modelos de linguagem diretamente no computador, testar novas IAs em poucos minutos e até criar aplicações próprias sem depender de serviços pagos.
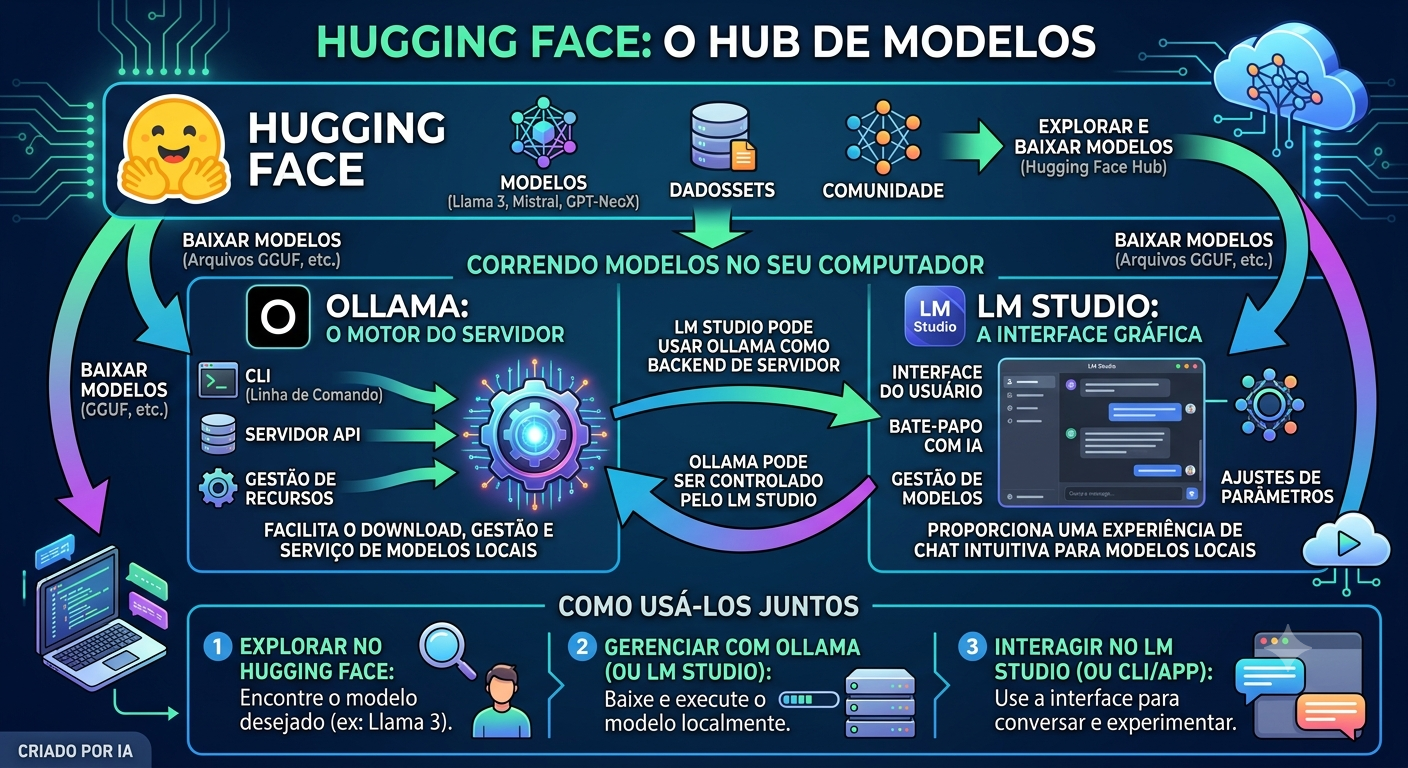
Nesse cenário, três nomes aparecem com frequência: Hugging Face, Ollama e LM Studio.
Muita gente trata essas ferramentas como se fossem concorrentes. Na prática, elas têm objetivos completamente diferentes — e costumam funcionar juntas. Neste artigo você vai entender para que serve cada uma e como elas podem fazer parte do seu dia a dia com IA.
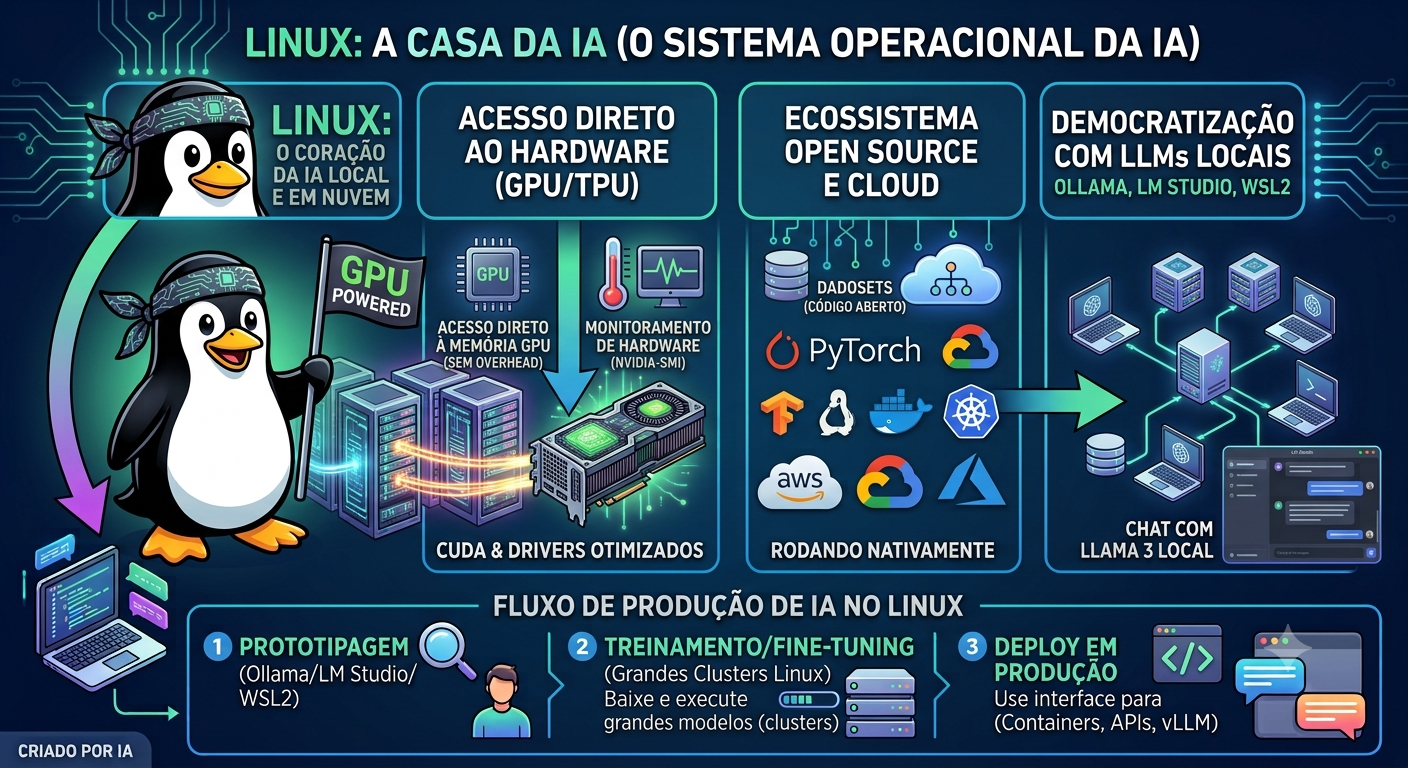
Modelos de IA local exigem memória RAM e, idealmente, uma GPU com VRAM suficiente. Um modelo de 7 bilhões de parâmetros em formato quantizado precisa de pelo menos 8 GB de RAM. Modelos maiores exigem mais. Antes de sair baixando, vale checar quanto de memória sua máquina tem — caso contrário o modelo vai travar ou nem carregar. E sim: Ollama e LM Studio rodam em Windows, macOS e Linux.
📦 Hugging Face: o GitHub da Inteligência Artificial
Imagine um enorme repositório onde pesquisadores e empresas publicam modelos de IA para qualquer pessoa utilizar. Essa é exatamente a proposta do Hugging Face.
Ali você encontra modelos da Meta, Google, Microsoft, Mistral AI, Qwen, DeepSeek e de centenas de pesquisadores independentes — prontos para baixar, testar ou integrar em aplicações.
Além dos modelos, a plataforma oferece conjuntos de dados (datasets), bibliotecas para desenvolvimento e os Spaces — demonstrações online onde você pode testar modelos diretamente pelo navegador, sem instalar nada. Para quem ainda não quer configurar nada localmente, os Spaces são uma ótima porta de entrada.
O que você pode fazer com o Hugging Face?
- Geração de texto e código
- Tradução e resumo de documentos
- Reconhecimento e geração de imagens
- Transcrição e síntese de voz
- Embeddings e classificação de textos
- E muito mais — são milhares de modelos
- Comparar modelos antes de escolher
- Testar pelo navegador nos Spaces
- Baixar modelos para uso local
- Encontrar datasets para treinamento
- Integrar modelos via API
- Acompanhar lançamentos da comunidade
Todo mundo que trabalha com IA acaba passando pelo Hugging Face — do iniciante que quer testar um modelo no browser ao desenvolvedor que precisa integrar um modelo em produção. É praticamente uma referência obrigatória.
⚙️ Ollama: execute modelos locais com um comando
Baixar um modelo não significa que ele já está pronto para uso. Os arquivos precisam ser carregados corretamente, a memória precisa ser gerenciada, e a comunicação com outros programas precisa de uma interface padronizada. É aqui que entra o Ollama.
O Ollama funciona como um gerenciador de modelos locais. Ele cuida de praticamente todo o trabalho complicado: baixa o modelo, organiza os arquivos, inicia o serviço, gerencia memória e disponibiliza uma API local — tudo com um comando simples.
ollama run qwen3
# Listar modelos instalados:
ollama list
# Trocar para outro modelo:
ollama run llama3.2
Em poucos minutos o modelo já está funcionando — sem configuração manual, sem precisar entender como carregar pesos ou gerenciar memória.
O que você pode fazer com o Ollama?
- Usar IA sem internet e sem custos por token
- Criar chatbots e assistentes locais
- Automatizar tarefas via API
- Desenvolver aplicações em Python
- Usar agentes de IA localmente
- Open WebUI (interface web local)
- Continue (assistente no VS Code)
- AnythingLLM (RAG local)
- LangChain e LlamaIndex
- N8n e outras ferramentas de automação
Desenvolvedores, entusiastas que não têm medo do terminal e quem quer integrar modelos em projetos próprios. O Ollama virou praticamente um padrão para IA local — se você vai criar algo com modelos locais, provavelmente vai passar por ele.
🖥️ LM Studio: IA local sem precisar de terminal
Nem todo mundo gosta — ou precisa — de usar o terminal. Foi pensando nisso que surgiu o LM Studio: uma interface gráfica completa para baixar, carregar e conversar com modelos de IA localmente.
Com alguns cliques você pesquisa modelos, faz o download, ajusta configurações de memória e GPU, inicia uma conversa e até sobe um servidor local compatível com a API da OpenAI — o que permite conectar outros programas ao modelo rodando na sua máquina.
O que você pode fazer no LM Studio?
- Pesquisar e baixar modelos
- Conversar com a IA como num chat
- Comparar modelos lado a lado
- Ajustar parâmetros de geração (temperatura, top-p)
- Configurar uso de GPU e memória
- Subir servidor local com API compatível com OpenAI
- Executar modelos GGUF
- Testar prompts e system prompts
- Conectar outros programas ao modelo local
- Usar sem internet e sem custo por token
Quem está começando com IA local e prefere uma experiência visual, sem terminal. Também é ótimo para quem quer testar e comparar modelos rapidamente, ajustar parâmetros e explorar o comportamento de diferentes IAs antes de decidir qual usar em um projeto.
🔄 Elas competem entre si?
Não. Cada uma resolve um problema diferente — e em muitos casos você vai usar as três.
| Ferramenta | Função principal | Perfil indicado |
|---|---|---|
| 📦 Hugging Face | Repositório de modelos, datasets e pesquisas | Todos — do iniciante ao pesquisador |
| ⚙️ Ollama | Gerenciamento e execução local via terminal e API | Desenvolvedores e quem cria aplicações |
| 🖥️ LM Studio | Interface gráfica para executar e testar modelos locais | Iniciantes e quem prefere evitar o terminal |
💡 Um exemplo prático: do zero ao modelo rodando
Imagine que você quer testar o modelo Qwen3 — um dos mais elogiados da comunidade no momento. Veja como as três ferramentas entram nesse fluxo:
Você acessa huggingface.co, busca “Qwen3” e verifica tamanho do modelo, licença de uso, avaliações da comunidade e qual versão faz mais sentido para o seu hardware. Se quiser, já testa pelo browser nos Spaces antes de baixar qualquer coisa.
Abre o terminal e digita ollama run qwen3. O Ollama baixa o modelo, organiza tudo e já inicia a conversa. Você também pode integrar esse modelo via API local em qualquer script Python ou ferramenta de automação.
Você abre o LM Studio, carrega o mesmo modelo e começa a ajustar parâmetros — temperatura, comprimento de resposta, system prompt. Compara o comportamento com outro modelo que você tem instalado. Tudo pela interface, sem digitar nada.
Com o modelo testado e aprovado, você usa a API local do Ollama ou do LM Studio para conectar a IA ao seu sistema — seja um script Python, uma automação no N8n, um RAG com seus documentos ou qualquer outra aplicação.
Cada ferramenta participou de uma etapa diferente — e nenhuma substituiu a outra. Esse é o fluxo mais comum de quem trabalha com IA local de forma séria.
🚀 Qual devo instalar primeiro?
Depende do seu objetivo — mas aqui vai um guia direto:
| Objetivo | Comece por |
|---|---|
| Quero apenas conversar com uma IA local sem complicação | 🖥️ LM Studio — mais simples e visual |
| Quero criar aplicações, automações ou integrar IA em projetos | ⚙️ Ollama — padrão para desenvolvimento local |
| Quero descobrir modelos, pesquisar e entender o que existe | 📦 Hugging Face — começa pelo browser, sem instalar nada |
| Quero tudo — aprender, testar e eventualmente criar algo | Hugging Face → LM Studio → Ollama, nessa ordem |
🎯 Resumo rápido
O crescimento da IA local abriu um caminho que há pouco tempo parecia restrito a grandes laboratórios: rodar modelos poderosos no seu próprio computador, sem depender de serviços pagos, sem mandar seus dados para nenhum servidor, sem limite de uso.
Entender o papel de cada ferramenta é o primeiro passo para montar um ambiente de IA local que realmente funcione — seja para aprender, criar aplicações ou simplesmente explorar o que essa tecnologia pode fazer por você.