Tem uma crença que se espalhou rápido no mundo da inteligência artificial — e que parece tão óbvia que quase ninguém questiona: quanto mais parâmetros um modelo tem, melhor ele é.
Essa lógica fez sentido por um tempo. Os modelos foram crescendo, os benchmarks foram melhorando, e a correlação parecia clara. Mas 2024 e 2025 quebraram essa narrativa de um jeito que ainda não foi bem absorvido pelo público geral.
Modelos menores começaram a superar modelos maiores em tarefas específicas. Empresas pararam de divulgar o número de parâmetros dos seus modelos. E a pergunta “quantos bilhões tem esse modelo?” foi ficando cada vez menos relevante.
Então o que realmente determina se uma IA é boa ou não? É sobre isso que eu quero falar aqui.
🔢 Primeiro: o que é um parâmetro, afinal?
Antes de desmontar o mito, vale entender o que estamos falando.
Um modelo de linguagem é, na essência, uma rede neural — uma estrutura matemática composta por camadas de nós conectados. Cada conexão entre esses nós tem um valor numérico associado: esse é o parâmetro.
Durante o treinamento, esses valores são ajustados bilhões de vezes até que o modelo consiga prever bem o próximo token em uma sequência de texto. Quando o treinamento termina, esses valores ficam “congelados” — e é aí que o modelo está pronto para uso.
Pensa nos parâmetros como os neurônios e conexões de um cérebro artificial. Mais conexões significa mais capacidade potencial de aprender padrões complexos. Mas só potencial — não garante nada sobre o resultado final.
Um modelo com 70 bilhões de parâmetros tem 70 bilhões desses valores numéricos. Um modelo com 7 bilhões tem dez vezes menos. A intuição de que “mais é melhor” vem daí — e não é completamente errada. Mas é muito incompleta.
📈 Como o mito se formou
Entre 2018 e 2023, havia uma tendência clara: os modelos maiores eram consistentemente melhores. O GPT-2 superou o GPT-1. O GPT-3 surpreendeu o mundo. O GPT-4 foi um salto enorme em relação ao GPT-3.
As empresas começaram a competir pelo tamanho dos modelos como se fosse uma corrida armamentista. Os anúncios vinham com números impressionantes — centenas de bilhões de parâmetros — como se isso fosse o dado mais importante sobre o modelo.
↓ melhorou
GPT-2 (2019) → 1,5 bilhão de parâmetros
↓ melhorou muito
GPT-3 (2020) → 175 bilhões de parâmetros
↓ saltou de patamar
GPT-4 (2023) → número não divulgado
↓ e aí a lógica começou a mudar
A virada aconteceu quando modelos menores e mais eficientes começaram a aparecer com desempenho comparável — às vezes superior — em tarefas específicas. E quando as próprias empresas pararam de divulgar o número de parâmetros dos seus melhores modelos.
A OpenAI não divulgou o número de parâmetros do GPT-4. A Anthropic nunca divulga os números do Claude. O Google não detalha o Gemini. Essa opacidade não é coincidência — é um sinal de que o número de parâmetros deixou de ser o diferencial competitivo mais importante.
💥 O que realmente determina a qualidade de um modelo
Se não é o número de parâmetros, o que é? A resposta honesta é: várias coisas ao mesmo tempo. E nenhuma delas aparece num anúncio de lançamento.
Um modelo treinado em dados ruins vai produzir resultados ruins, independentemente do tamanho. Curadoria, limpeza e diversidade dos dados de treino têm impacto enorme no resultado final — e são muito menos “fotogênicos” do que um número com nove zeros.
A forma como os parâmetros são organizados importa tanto quanto a quantidade. Inovações na arquitetura — como atenção eficiente, Mixture of Experts, e outros avanços — permitem que modelos menores façam o que modelos maiores de gerações anteriores faziam.
Um modelo base com 70 bilhões de parâmetros que nunca passou por instruction tuning vai ser muito pior como assistente do que um modelo de 7 bilhões que foi cuidadosamente ajustado para seguir instruções, evitar erros e se comunicar bem. O pós-treinamento é onde muito do valor real é criado.
Não existe modelo universalmente melhor. Um modelo gigantesco pode ser extraordinário em raciocínio matemático e medíocre em criatividade narrativa. Um modelo pequeno e especializado pode dominar uma tarefa específica e falhar em qualquer outra coisa. “Melhor” sempre depende do contexto.
Um modelo com menos parâmetros treinado em muito mais dados pode superar um modelo maior treinado em menos dados. A relação entre tamanho do modelo e volume de treinamento é um campo de pesquisa ativo — e os resultados mostram que muitos modelos grandes foram “subtreinados” em relação ao seu potencial.
🧪 O caso concreto que virou o jogo
Em 2023, a Meta lançou o Llama — uma família de modelos abertos com versões de 7, 13, 33 e 65 bilhões de parâmetros. A comunidade de pesquisa ficou animada, mas a expectativa era que esses modelos fossem claramente inferiores aos gigantes proprietários.
O que aconteceu foi diferente. Em poucas semanas, pesquisadores e desenvolvedores ao redor do mundo começaram a aplicar fine-tuning nesses modelos menores usando conjuntos de dados cuidadosamente curados — e os resultados foram surpreendentes. Modelos de 13 bilhões de parâmetros ajustados passaram a competir com modelos proprietários muito maiores em diversas tarefas.
Dados de qualidade + fine-tuning inteligente > tamanho bruto do modelo. Não em todos os casos e não em todas as tarefas. Mas o suficiente para quebrar a ideia de que você precisa de centenas de bilhões de parâmetros para ter uma IA útil e capaz.
Isso abriu um caminho que hoje é cada vez mais explorado: modelos especializados, menores, eficientes — que fazem uma coisa muito bem em vez de fazer tudo razoavelmente.
⚡ A nova corrida: eficiência, não tamanho
Se antes a competição era “quem tem o modelo maior”, hoje ela mudou de eixo. As perguntas que importam agora são outras:
- Quantos bilhões de parâmetros?
- Qual o maior modelo possível?
- Quanto de compute foi usado?
- Qual modelo vence o benchmark geral?
- Qual o menor modelo que resolve esse problema?
- Quanto custa rodar por token?
- Pode rodar localmente, sem internet?
- Qual modelo vence nessa tarefa específica?
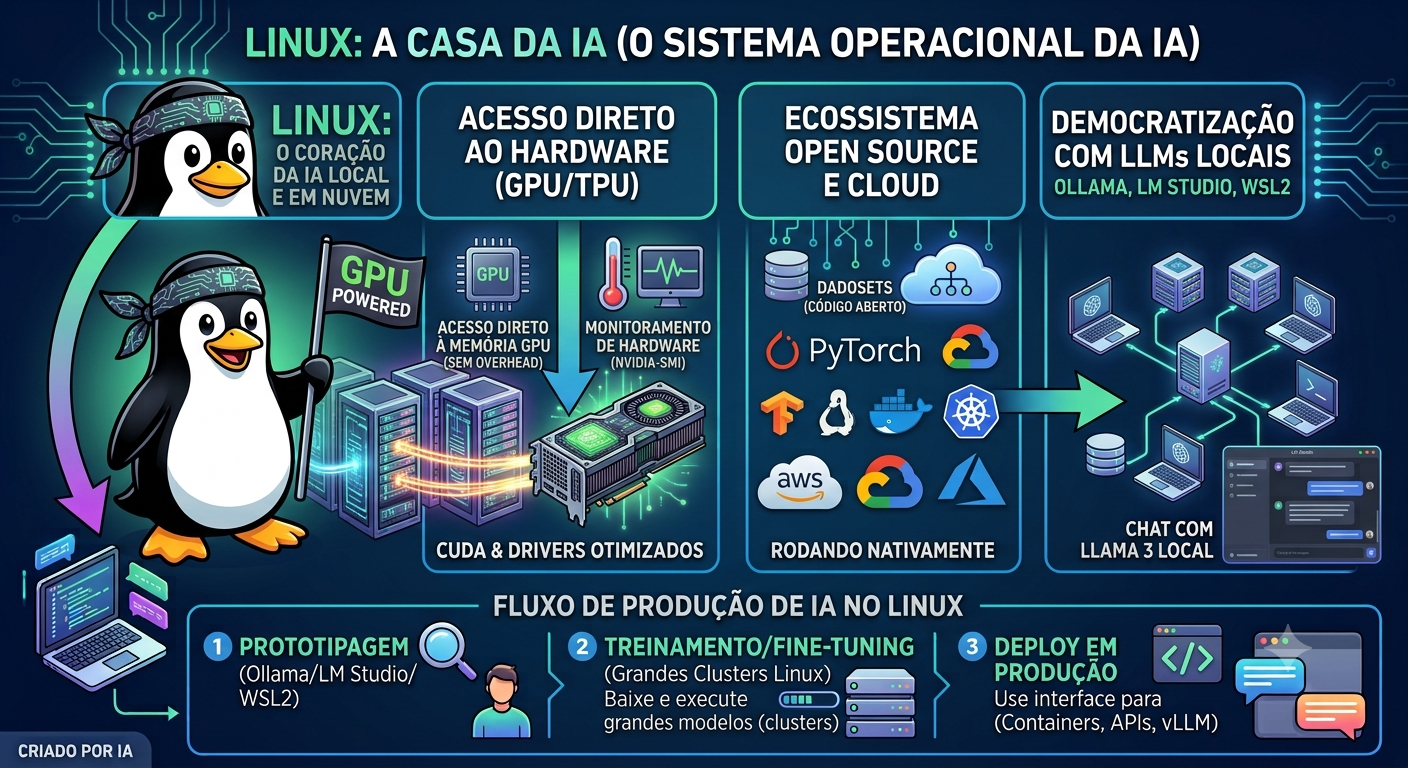
Isso tem implicações práticas enormes. Um modelo que roda localmente num notebook — sem mandar seus dados para nenhum servidor — pode ser exatamente o que uma empresa pequena precisa. Não porque é o “mais inteligente”, mas porque resolve o problema, preserva a privacidade e custa infinitamente menos.
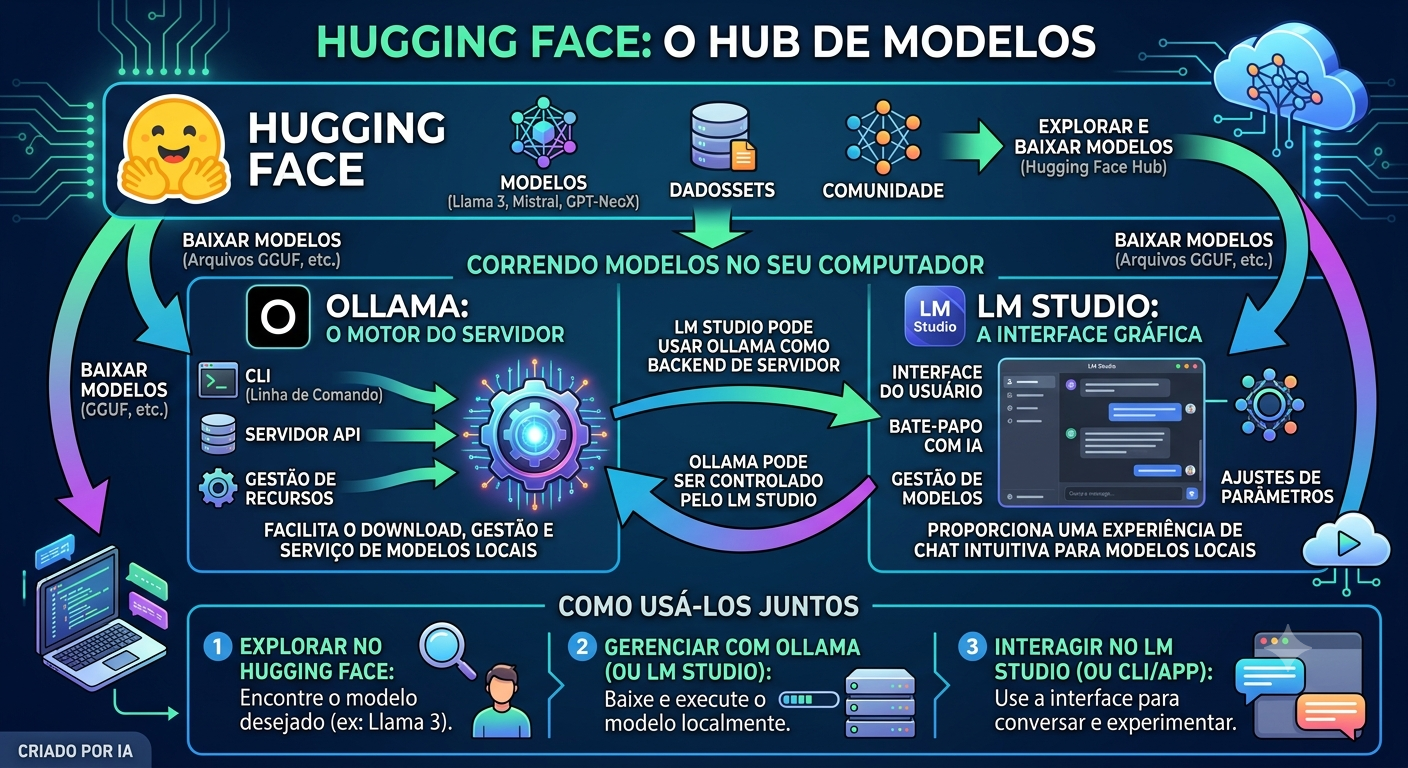
Ferramentas como o Ollama permitem rodar modelos como Llama, Mistral, Phi e Gemma diretamente no seu computador — sem GPU de última geração, sem conta em nenhuma plataforma, sem custo por token. Um modelo de 7 bilhões de parâmetros bem ajustado rodando localmente resolve 80% dos casos de uso que a maioria das pessoas tem no dia a dia.
📊 O problema dos benchmarks
Outro fator que alimenta o mito dos parâmetros é a forma como os modelos são comparados publicamente: os benchmarks.
Um benchmark é um conjunto padronizado de testes — perguntas de matemática, lógica, conhecimento geral, código — que permite comparar modelos numa escala comum. Na teoria, é uma boa ideia. Na prática, virou um campo minado.
| O problema | O que acontece na prática |
|---|---|
| Overfitting em benchmarks | Modelos são otimizados especificamente para os testes mais populares. Ótimo no benchmark, medíocre no uso real. |
| Contaminação de dados | As respostas dos benchmarks podem ter vazado nos dados de treinamento. O modelo “memorizou” as respostas, não aprendeu o raciocínio. |
| Benchmarks não testam tudo | Criatividade, nuance, contexto cultural, consistência em conversas longas — coisas que importam no uso real raramente aparecem nos testes padronizados. |
| Cherry-picking | Empresas escolhem divulgar os benchmarks onde se saem melhor e ignoram os onde ficam mal. Você compara o melhor deles com o melhor de outro — e nenhum número é representativo. |
A melhor forma de avaliar um modelo é testá-lo nas tarefas que você realmente vai usar. Benchmark alto e parâmetros em bilhões não garantem que ele vai funcionar bem para o seu caso específico.
🇧🇷 Por que isso importa para o Brasil
Existe uma consequência prática desse mito que afeta diretamente o Brasil: a crença de que desenvolver IA competitiva exige infraestrutura absurda, investimento bilionário e acesso a hardware que apenas as big techs americanas têm.
Isso é parcialmente verdade para os modelos de fronteira — os maiores e mais capazes. Mas o espaço de modelos especializados, menores e eficientes é exatamente onde um país como o Brasil pode e deveria estar atuando.
Um modelo treinado com dados jurídicos brasileiros, em português, com conhecimento das particularidades do direito administrativo nacional, vai superar qualquer modelo americano genérico nessa tarefa específica — mesmo sendo dez vezes menor. O mesmo vale para saúde pública, agronegócio, educação.
A corrida pelos modelos gigantes já foi — e perdemos. Mas a corrida pelos modelos especializados, eficientes e culturalmente relevantes ainda está aberta. E essa é justamente a corrida onde dados de qualidade e conhecimento de domínio valem mais do que infraestrutura bruta.
🎯 Resumo: o que realmente importa
Na próxima vez que você ver um anúncio de modelo com “X bilhões de parâmetros” em destaque, saiba que esse número diz menos sobre a qualidade do modelo do que qualquer empresa gostaria que você acreditasse.
O que importa é o que o modelo consegue fazer — na sua tarefa, com seus dados, no seu contexto. E isso só se descobre testando. Não lendo o press release.