Textos coletados da internet, bilhões de cálculos, meses de treinamento e centenas de milhões de dólares.
Mas o que acontece exatamente? E qualquer pessoa poderia criar uma IA?
Conceito base
O que é uma LLM?
LLM significa Large Language Model — ou, em português, Modelo de Linguagem de Grande Escala. É o tipo de tecnologia que está por trás do ChatGPT, do Google Gemini, do Claude da Anthropic e da maioria das IAs conversacionais que você já usou.
Em termos simples: uma LLM é um programa de computador que aprendeu a entender e gerar texto lendo quantidades absurdas de conteúdo escrito por humanos — livros, artigos, sites, fóruns, código, conversas — e identificando padrões nesse texto.
Mas “identificar padrões” é uma descrição muito tímida do que acontece. O que essas IAs fazem é aprender a prever: dado um texto, qual seria a próxima palavra mais provável? E a seguinte? E a seguinte? Repetido bilhões de vezes, esse processo produz algo que parece, de fora, como compreensão.
Imagine que você leu todos os livros já escritos em português. Toda a Wikipedia. Todo o conteúdo da internet. Depois, alguém te mostra a frase “O Brasil é o maior país da América” e pergunta: “qual a próxima palavra?” Você provavelmente diria “do Sul”. Não porque alguém te ensinou essa frase específica — mas porque você absorveu tantos padrões da língua que a resposta emerge naturalmente. É exatamente assim que uma LLM funciona, só que em escala incompreensivelmente maior.
O termo “Large” (grande) no nome não é modéstia invertida. Os modelos modernos têm dezenas a centenas de bilhões de parâmetros — números internos que o modelo ajusta durante o treinamento para ficar melhor em suas previsões. O GPT-3, lançado em 2020, tinha 175 bilhões. Os modelos atuais chegam a trilhões.
O processo completo
As etapas de criação — do texto ao modelo
Criar uma LLM não é um único processo. São várias etapas encadeadas, cada uma com sua própria complexidade técnica. Veja abaixo o caminho completo:
Tudo começa com texto. Muito texto. As empresas de IA rastreiam a internet inteira — sites, blogs, fóruns, Wikipedia, livros digitalizados, artigos científicos, repositórios de código — e armazenam esse conteúdo bruto. O projeto Common Crawl, por exemplo, arquiva bilhões de páginas da web e é uma das fontes mais usadas. O FineWeb, da Hugging Face, processou mais de 15 trilhões de tokens extraídos dessas fontes.
corpus bruto
A internet está cheia de lixo. Spam, conteúdo duplicado, textos sem sentido, páginas em idiomas misturados, conteúdo inadequado. Antes de qualquer treinamento, equipes inteiras de engenheiros desenvolvem sistemas para filtrar, deduplicar e classificar esse material. O objetivo é garantir que o modelo aprenda com texto de qualidade, não com ruído. Essa etapa pode levar meses e é subestimada na maioria das explicações públicas.
limpeza · deduplicação · filtragem
Computadores não entendem palavras — entendem números. A tokenização é o processo de dividir o texto em pequenas unidades chamadas tokens e atribuir um número a cada uma. Um token pode ser uma palavra inteira, parte de uma palavra, um sinal de pontuação ou até um espaço. A frase “Bom dia!” vira, por exemplo, [33421, 8621, 0]. O modelo só vai ver esses números durante todo o treinamento.
→
[“Bom”, ” dia”, “!”]
→
[33421, 8621, 0]
Antes do treinamento, é preciso definir o vocabulário — o conjunto de todos os tokens que o modelo vai conhecer (normalmente entre 32.000 e 128.000 tokens). Um algoritmo chamado Byte Pair Encoding (BPE) é usado para construir esse vocabulário de forma eficiente, quebrando palavras raras em pedaços menores.
BPE · vocabulário · tokens
Antes de processar os tokens, o modelo os transforma em vetores — listas de centenas ou milhares de números que representam o “significado” daquele token num espaço matemático multidimensional. Pense como um mapa: palavras com significados parecidos ficam próximas nesse mapa. Gato e cachorro ficam perto. Gato e avião ficam longe.
Imagine que cada palavra tem um endereço num mapa com 768 dimensões (impossível visualizar, mas a lógica é a mesma de um mapa 2D). O modelo aprende esses endereços durante o treino. Depois, você consegue fazer contas com palavras: “rei” − “homem” + “mulher” ≈ “rainha”. O modelo descobriu essa relação sozinho, só lendo texto.
vetores · dimensões · espaço semântico
Em 2017, pesquisadores do Google publicaram um artigo chamado “Attention is All You Need” que mudou a história da IA. Eles propuseram uma nova arquitetura chamada Transformer, que resolveu um problema antigo: como fazer o modelo prestar atenção nas partes certas de um texto ao gerar uma resposta?
O mecanismo de atenção (Attention) permite que, ao processar a palavra “banco” numa frase como “O banco estava cheio de gente”, o modelo olhe para as outras palavras ao redor — “cheio”, “gente” — e entenda que estamos falando de um banco de assento, não de uma instituição financeira.
Essa arquitetura é a base de praticamente todo LLM moderno: GPT, Claude, Gemini, LLaMA, Mistral — todos usam Transformers.
Transformer · Self-Attention · Multi-Head Attention
Aqui começa o treinamento de verdade. O modelo recebe bilhões de fragmentos de texto e tenta prever, para cada posição, qual seria o próximo token. Quando erra, um algoritmo chamado backpropagation propaga o erro de volta pelo modelo e ajusta levemente todos os seus parâmetros internos. Isso se repete bilhões de vezes.
O resultado não é “o modelo memorizou os textos”. É que o modelo desenvolveu uma representação interna da linguagem — gramática, fatos, relações entre conceitos, raciocínio — tudo emergindo do simples ato de prever a próxima palavra, repetido à exaustão.
O GPT-3 foi treinado em 300 bilhões de tokens, durante semanas, usando centenas de GPUs rodando 24h por dia. O custo estimado desse treinamento foi de US$ 4 a 12 milhões só em computação.
loss · backpropagation · gradiente
Um modelo pré-treinado sabe completar textos, mas não necessariamente sabe responder perguntas ou seguir comandos. O Instruction Tuning resolve isso: o modelo é treinado novamente, agora com exemplos do tipo “pergunta → resposta ideal”, ensinando-o a se comportar como um assistente.
Esse processo usa conjuntos de dados menores, mas altamente curados — escritos ou revisados por humanos. É aqui que o modelo aprende a diferença entre “completar um texto” e “ajudar alguém”.
Supervised Fine-Tuning (SFT) · instruction pairs
RLHF significa Reinforcement Learning from Human Feedback — Aprendizado por Reforço com Feedback Humano. É a etapa que faz a diferença entre um modelo que responde qualquer coisa e um que responde de forma útil, honesta e segura.
O processo funciona assim: avaliadores humanos comparam diferentes respostas do modelo e dizem qual é melhor. Com essas avaliações, treina-se um modelo de recompensa que aprende a prever o que humanos preferem. Então, o LLM é ajustado para maximizar essa recompensa — essencialmente, para produzir respostas que humanos avaliadores considerariam boas.
RLHF · DPO · reward model · PPO
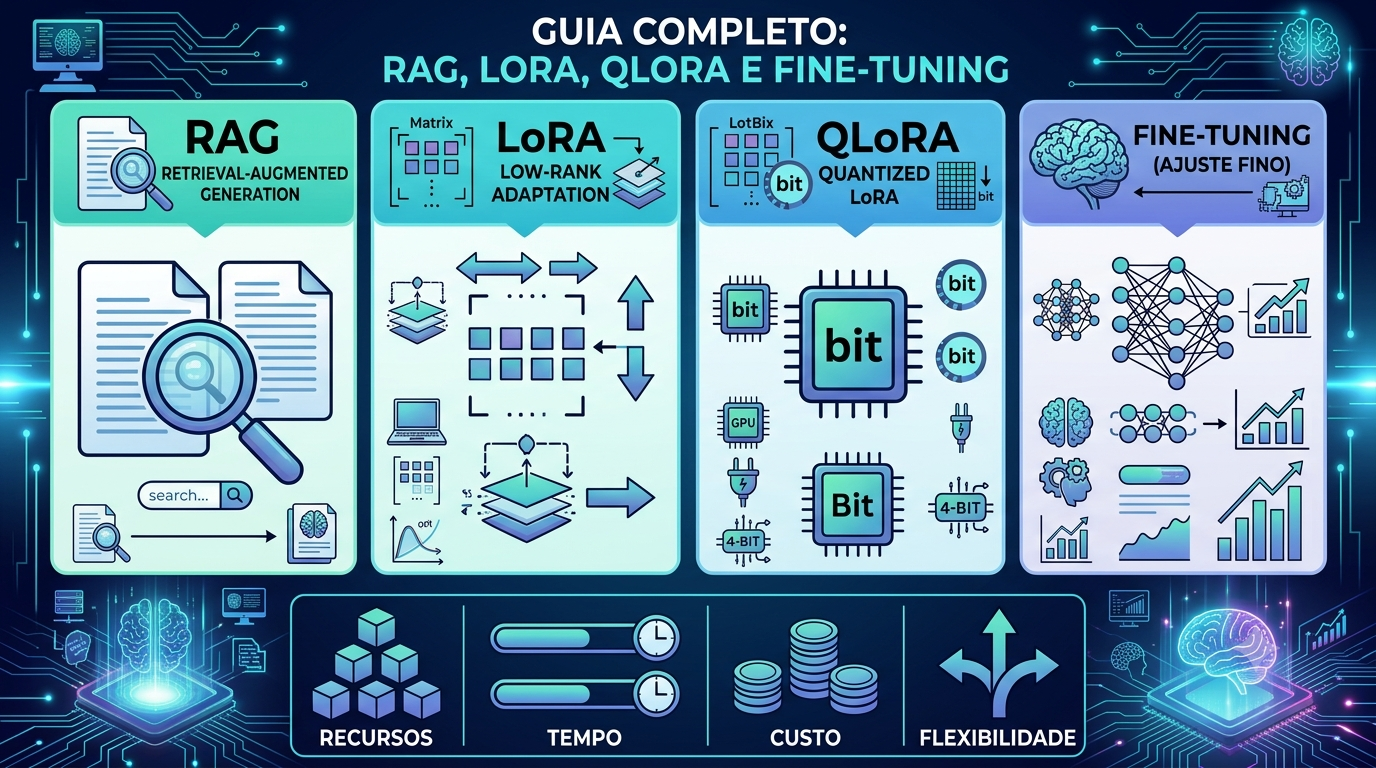
Depois de todo esse processo, o modelo base pode ser adaptado para usos específicos através do fine-tuning (ajuste fino). Quer um modelo especialista em medicina? Em código Python? Em atendimento ao cliente em português? Fine-tuning é o caminho.
Uma técnica chamada LoRA (Low-Rank Adaptation) tornou isso acessível: em vez de retreinar o modelo inteiro — o que exigiria a mesma infraestrutura cara do pré-treinamento — o LoRA adiciona pequenos “módulos” ao modelo e treina só eles. O resultado é quase igual com um custo muito menor.
LoRA · QLoRA · domain adaptation
Antes de chegar até você, o modelo passa por um processo de otimização para produção: quantização (reduzir o tamanho sem perder muita qualidade), compilação para GPUs específicas, e configuração de infraestrutura de serviço capaz de responder milhões de requisições por dia.
Quando você digita algo no ChatGPT e pressiona Enter, o seu texto vira tokens → vira números → percorre dezenas de camadas do modelo → o modelo prevê o próximo token → e assim por diante, até a resposta completa aparecer. Tudo isso em frações de segundo.
quantização · vLLM · inferência · API
Bastidores
A infraestrutura necessária
Para treinar um LLM de grande escala, não basta um computador potente. É necessária uma infraestrutura que poucas organizações no mundo conseguem montar.
GPUs (as mesmas placas usadas para jogos, mas em versões industriais) são essenciais porque fazem milhares de cálculos simultaneamente. Uma GPU de ponta como a NVIDIA H100 custa entre US$ 25.000 e US$ 40.000. Treinar um modelo grande pode exigir centenas ou milhares delas rodando em paralelo durante semanas.
Com centenas de GPUs trabalhando juntas, a velocidade de comunicação entre elas é crítica. Tecnologias como InfiniBand e NVLink permitem que as GPUs troquem dados a velocidades muito maiores que redes comuns. O gargalo de comunicação pode desperdiçar mais tempo de GPU do que o próprio cálculo.
Os dados de treinamento podem chegar a terabytes ou petabytes. É preciso armazenamento de alta performance que consiga alimentar as GPUs continuamente sem criar filas de espera. SSDs de datacenter e sistemas de arquivos distribuídos são obrigatórios.
Um cluster de GPUs gera calor equivalente a dezenas de saunas. Datacenters de IA consomem megawatts de energia elétrica — o suficiente para abastecer cidades inteiras. O resfriamento, frequentemente a água, é um dos maiores custos operacionais.
Na prática, apenas Google, Microsoft, Meta, Amazon e a OpenAI têm capacidade de treinar modelos de escala máxima. Outros players — como Mistral, Cohere e a própria Anthropic — alugam essa computação das nuvens (AWS, Azure, GCP) pagando por hora de uso de GPU. Mesmo assim, os custos chegam a dezenas de milhões de dólares por modelo.
O dinheiro por trás
Por que custa tanto?
A pergunta que todo mundo faz: “Mas por que é tão caro? Não é só computador?” É computador, sim — mas em quantidades e especificações que poucos conseguem imaginar.
“Treinar o GPT-4 custou entre US$ 50 e 100 milhões em computação. Isso sem contar salários de engenheiros, dados e infraestrutura de serviço.”
| Componente de custo | O que envolve | Estimativa |
|---|---|---|
| Computação de treino | Horas de GPU multiplicadas por centenas de máquinas durante semanas | US$ 5M – 100M+ |
| Dados e curadoria | Coleta, limpeza, filtragem e anotação humana de datasets | US$ 1M – 20M |
| RLHF / anotadores | Equipes humanas avaliando respostas por meses | US$ 1M – 10M |
| Pesquisa e engenharia | Salários de pesquisadores de IA — dos mais caros do mercado | US$ 10M – 50M/ano |
| Inferência (serviço) | GPU rodando 24h para responder usuários em tempo real | US$ milhões/mês |
| Energia elétrica | Consumo contínuo de megawatts nos datacenters | Incluso acima |
Além do custo financeiro, existe o custo ambiental: treinar um único modelo grande emite centenas de toneladas de CO₂. Esse debate está cada vez mais presente na comunidade de IA.
A boa notícia é que os custos têm caído rapidamente. O que custava US$ 100 milhões em 2020 pode ser replicado por US$ 5 milhões em 2025, graças a hardware melhor, técnicas mais eficientes e competição de mercado. Modelos menores e especializados já são acessíveis para empresas médias.
A grande questão
Qualquer pessoa pode criar uma IA?
Depende do que você chama de “criar uma IA”. A resposta honesta é: sim e não, dependendo da escala.
Treinar um modelo do tamanho do GPT-4 ou Claude do zero. Isso exige infraestrutura de datacenter, centenas de milhões de dólares e equipes de dezenas de pesquisadores de elite. Está restrito a grandes empresas de tecnologia.
Usar modelos open-source (LLaMA, Mistral, Gemma), fazer fine-tuning com técnicas como LoRA em GPUs comuns, criar chatbots com RAG, e até treinar modelos pequenos do zero para aprendizado. Isso já é possível num laptop relativamente moderno.
A democratização dos modelos open-source foi um divisor de águas. Quando a Meta lançou o LLaMA — e depois o LLaMA 2, 3 e 3.1 — com pesos abertos para uso livre, qualquer pessoa com um computador razoável passou a conseguir rodar modelos de linguagem poderosos localmente.
Ferramentas como Ollama permitem rodar modelos como LLaMA 3, Mistral e Gemma diretamente no seu computador, sem internet, sem custo por requisição. O Hugging Face disponibiliza milhares de modelos gratuitamente. O Google Colab oferece GPUs gratuitas para experimentação. A barreira de entrada caiu drasticamente — o que era impossível em 2020 está ao alcance de um entusiasta em 2025.
A distinção importante é entre treinar do zero e adaptar um modelo existente. Treinar do zero ainda exige recursos imensos. Mas pegar um modelo já treinado e adaptá-lo para um caso de uso específico com fine-tuning — isso qualquer desenvolvedor com motivação e um curso decente consegue fazer.
Oportunidades
Quanto custa entrar na área?
Se você está pensando em entrar na área de IA — seja como desenvolvedor, pesquisador ou criador de soluções — a boa notícia é que o investimento inicial é muito menor do que parece.
| Nível | O que você pode fazer | Investimento estimado |
|---|---|---|
| 🆓 Gratuito | Usar APIs gratuitas (Gemini, OpenAI free tier), rodar modelos locais com Ollama, experimentar no Google Colab, estudar cursos gratuitos (fast.ai, Hugging Face, YouTube) | R$ 0 |
| 💡 Iniciante | Computador com 16GB RAM e GPU dedicada (RTX 3060+), cursos pagos (deeplearning.ai, Coursera), acesso a APIs pagas para projetos reais | R$ 3.000 – 8.000 |
| 🚀 Profissional | GPU de alto desempenho (RTX 4090 ou A100 na nuvem), fine-tuning de modelos médios, deploy de aplicações reais | R$ 15.000 – 50.000 |
| 🏢 Empresa | Fine-tuning de modelos grandes, deploy escalável, equipe dedicada de engenheiros | R$ 200.000+/ano |
O mais importante não é o hardware — é o conhecimento. Um desenvolvedor que entende profundamente como os modelos funcionam, sabe fazer fine-tuning, montar sistemas de RAG e colocar soluções em produção vale mais do que alguém com acesso a computadores caros mas sem esse entendimento.
Os salários na área de IA refletem isso: engenheiros de machine learning e pesquisadores de IA estão entre os profissionais mais bem pagos do mundo tecnológico. No Brasil, a demanda por profissionais com esse perfil está crescendo rapidamente e ainda há poucos especialistas disponíveis.
Python + PyTorch → entender embeddings e RAG → montar um chatbot com documentos próprios → fazer fine-tuning de um modelo pequeno → aprender sobre Transformers por dentro. Esse caminho, seguido de forma consistente ao longo de 1 a 2 anos, coloca qualquer pessoa num nível profissional relevante na área.